В. В. Семенюк (e-mail: ecoding@mail.ru)
Все права защищены. Допускается использование данного материала с обязательным указанием авторства и предварительным уведомлением автора. Особо приветствуются вопросы, замечания и конструктивные предложения.
Автор выражает благодарность Максиму Захарову,
своевременно предоставившему некоторые материалы для данной работы.
1. Сжатие при передаче информации: алгоритмы, протоколы, стандарты
Раздел посвящен рассмотрению основных коммуникационных протоколов и стандартов, описывающих использование тех или иных алгоритмов сжатия при передаче информации. Вначале рассматриваются модемные протоколы MNP, стандарт V.42bis, протокол управления сжатием CCP, а также методики сжатия заголовков пакетов передачи информации. Затем вкратце описывается принцип действия метода ADPCM, наиболее часто используемого для сжатия аудио сигналов.
1.1 Протокол MNP
Протокол MNP (Microcom Networking Protocol) был разработан Microcom Inc. для модемов, выпускаемых фирмой. В нем описываются различные параметры и процедуры передачи информации, такие как формат передачи битов, тип модуляции, метод коррекции ошибок и т. д. Все спецификации протокола подразделяются на классы (уровни). Классы 5 и 7 (следуя традиции, в дальнейшем изложении будем называть их протоколами MNP5 и MNP7) имеют отношение к сжатию информации. MNP оказался достаточно удачным протоколом и используется в большинстве современных модемов.
Из двух указанных протоколов, регламентирующих способы сжатия информации, наибольшее распространение получил протокол MNP5. MNP5 регламентирует использование двухуровневой схемы сжатия, на первом уровне которой применяется групповое кодирование (RLE), а на втором - адаптивное префиксное кодирование. Обработка информации производится в два этапа: сначала информация подвергается обработке групповым кодированием, а затем полученная кодовая последовательность “дожимается” с использованием префиксного кодирования. Рассмотрим детально каждый алгоритм.
Реализация группового кодирования в протоколе MNP5 выглядит несколько нестандартно. Если в процессе обработки информации встретились три и более идущих подряд одинаковых символа, первые три из них выводятся в их исходном (незакодированном) виде, после чего на выход поступает число в восьмибитовом представлении, определяющее, сколько еще идентичных символов следует за данными тремя. К примеру, последовательность “abaabaaabaaaaa” будет закодирована на выходе алгоритма группового кодирования как “abaabaaa0baaa2”. Заметим, что в случае следования подряд только трех символов за ними все равно должно выводится число повторений, даже несмотря на то, что оно равно нулю. Это необходимо для того, чтобы декодер в процессе работы мог правильно интерпретировать кодовую последовательность. Каждый раз, когда в процессе декодирования будет встречена последовательность из трех одинаковых октетов, очередной октет будет рассматриваться как число повторений.
В протоколе MNP5 вводится ограничение на количество идентичных символов, одновременно обрабатываемых с помощью группового кодирования. Как ни странно, это количество ограничивается значением 250, а не 255, что более логично с учетом того, что для представления числа повторений используется восьмибитовое кодовое пространство. 5 неиспользуемых значений зарезервированы в протоколе для служебных целей.
Адаптивное префиксное кодирование, применяемое на втором уровне рассматриваемой схемы сжатия, использует статическую систему префиксных кодов. Каждый префиксный код в системе может быть условно разделен на головную часть длиной в три бита и остаточную часть, длина которой может варьироваться в интервале от 1 бита до 8 битов. Головная часть указывает одну из восьми групп, на которые подразделяются все префиксные коды в системе. Коды, принадлежащие одной группе, за исключением последней группы, имеют одинаковую длину остаточной части. Восемь групп содержат соответственно 2, 2, 4, 8, 16, 32, 64, 129 кодов. Система префиксных кодов выглядит следующим образом (знак “|” делит префиксный код на его головную и остаточную части; группы заключены в фигурные скобки): {“000|0”, “000|1”}, {“001|0”, “001|1”}, {“010|00”, ..., “010|11”}, {“011|000”, ... ,“011|111”}, {“100|0000”, ... ,“100|1111”}, {“101|00000”, ... , “101|11111”}, {“110|000000”, .... ,“110|111111”}, {“111|0000000”, ... ,“111|1111110”, “111|11111110”, “111|11111111”}.
Как видно, система содержит 257 префиксных кодов. 256 из них предназначены для кодирования символов, а оставшийся один - “111|11111111” - зарезервирован для служебных целей: он всегда ставится в конце передаваемого сообщения.
Адаптивное кодирование сопряжено со сбором статистики появления символов в обработанной части информации. В данном случае учитывается вся обработанная информация, а не какой-то фрагмент. Для этого каждому из 256 символов алфавита ставится в соответствие счетчик частоты появления данного символа в обработанной информации. Особенность сбора статистики состоит в том, что счетчик увеличивается только в случае, когда обработанный байт представляет собой символ в незакодированном представлении. Таким образом, октеты, соответствующие числу повторений, при сборе статистики не учитываются.
Проблема переполнения счетчиков в рассматриваемой схеме решается следующим образом: если некоторый счетчик достигает своего предельного значения, равного 255, производится масштабирование счетчиков с коэффициентом 2.
В процессе обработки информации символам алфавита динамически присваиваются префиксные коды из приведенной выше системы. Присвоение происходит с учетом частоты появления символа в обработанной части информации, определяемой по соответствующему значению счетчика - символам, встречающимся реже по сравнению с другими символами, должны соответствовать и более короткие коды (процедура динамического присваивания кодов строго регламентируется). Обработка каждого символа (в качестве символа может выступать число повторений) включает в себя три операции: замену символа префиксным кодом при кодировании или интерпретацию префиксного кода при декодировании, обновление счетчика, соответствующего данному символу и, в случае необходимости, изменение соответствия между символами и префиксными кодами.
Описанный алгоритм сжатия обладает малой эффективностью. К примеру, объем обычного представления текстовой информации, как правило, может быть уменьшен с применением данного алгоритм не более чем в полтора раза. Большей эффективностью обладает алгоритм, лежащий в основе протокола MNP7.
Протокол MNP7 предписывает использование несколько иной схемы сжатия, которая также включает в себя два уровня обработки информации. Первый уровень почти полностью повторяет первый уровень рассмотренной выше схемы сжатия за исключением того, что для записи числа повторений в групповом кодировании здесь используется не 8, а 4 бита (максимальное количество повторяющихся символов, одновременно обрабатываемых групповым кодированием, равно 18). Однако на втором уровне схемы применяется алгоритм, отличный от алгоритма второго уровня протокола MNP5.
Кодирование каждого символа на втором уровне схемы осуществляется с учетом предыдущего встретившегося символа. При этом используется статическая система кодов переменной длины, отличная от той, которая была описана выше. Во время обработки информации производится сбор статистики появления символов в контексте символа, непосредственно им предшествующего. Таким образом, количество счетчиков появлений символов составляет уже не 256, а 256*256 = 65536 (число всевозможных пар вида <символ-предшественник, текущий символ>). Префиксные коды распределяются строго с учетом частоты появления. В отличие от предыдущей схемы, здесь учитывается частота появления не одного символа, а сразу двух (точнее, одного в контексте другого).
Рассмотренный вкратце алгоритм эффективен для информации, в которой часто встречаются одинаковые символьные сочетания (таким свойством, например, обладает текстовая информация). Эксперименты показывают, что в некоторых случаях данный алгоритм в полтора раза опережает по степени сжатия алгоритм, лежащий в основе протокола MNP5. К сожалению, протокол MNP7 не завоевал должной популярности, что, вероятнее всего, произошло по причине повсеместного внедрения весьма перспективного стандарта сжатия информации V.42bis.
1.2 Стандарт V.42bis
Стандарт V.42bis предложен международным консультативным комитетом по телеграфии и телефонии (CCITT) [23]. В нем описывается процедура сжатия информации, рекомендуемая для использования в оконечном сетевом оборудовании телефонных линий связи. Стандарт V.42bis является на сегодняшний день одним из наиболее распространенных стандартов сжатия информации при ее передаче по коммуникационным каналам.
Алгоритм сжатия, предложенный в стандарте V.42bis, основан на словарном алгоритме LZW. Необходимо отметить, что, вопреки бытующему мнению о полной идентичности данных алгоритмов, алгоритм, рекомендованный комитетом CCITT, и алгоритм LZW имеют существенные отличия.
Согласно стандарту V.42bis, во время работы алгоритма сжатия поддерживается словарь, представленный совокупностью из 256 деревьев (лес), каждое из которых соответствует тому или иному символу алфавита сообщений (подразумевается, что используется восьмибитовое представление исходной информации; вообще говоря, стандарт допускает использование произвольного алфавита). При инициализации словаря каждое дерево содержит ровно по одному корневому узлу. Каждому узлу в дереве присваивается уникальный индекс. Количество индексов на начальном этапе кодирования равно 259: 256 индексов соответствуют 256 корневым узлам деревьев, а оставшиеся 3 зарезервированы для служебных целей (см. ниже).
При обработке информационной последовательности осуществляется поиск строки в словаре, имеющей наибольшее совпадение с началом кодируемой символьной последовательности. Процедура поиска аналогична процедуре поиска, используемой в алгоритме LZW. Поиск начинается с корневого узла и ведется последовательным сравнением символов, соответствующих узлам дерева, проходимым при его обходе по маршруту, определяемому кодируемой символьной последовательностью. Поиск заканчивается в одном из двух случаев:
1. найдено наибольшее совпадение;
2. произошло служебное событие.
Найденной строке в словаре соответствует некоторый индекс. Данный индекс и выступает в качестве кода. Объем кодового пространства определяется общим количеством задействованных индексов и, как правило, находится в логарифмической зависимости от этого количества. В соответствии со стандартом V.42bis, изменение длины кодовой комбинации в процессе кодирования должно сопровождаться выводом в выходной поток служебного индекса STEPUP. После интерпретации данного индекса в процессе декодирования размер кодовой комбинации должен быть увеличен на 1 бит, причем вне зависимости от того, было ли полностью исчерпано предыдущее кодовое пространство или нет.
Существует ситуация, при которой, в соответствии со стандартом, найденная строка должна быть отвергнута, и при кодировании должен быть задействован индекс строки, полученной удалением из найденной строки крайнего правого символа (такая "урезанная" строка всегда принадлежит словарю, что обуславливается способом включения строк в словарь). Это случай, когда найденная строка была добавлена в словарь на этапе кодирования, непосредственно предшествующем текущему. Данное ограничение обусловлено стремлением упростить процесс декодирования (интерпретация индекса строки, добавленной в словарь на предыдущем этапе кодирования, вызывает в процессе декодирования некоторые затруднения).
Служебное событие инициируется извне и связано с необходимостью изменения режима или параметров кодирования. В качестве примера служебного события можно привести запрос на реинициализацию словаря (C-INIT), при поступлении которого словарь должен быть незамедлительно приведен в свое начальное состояние.
Добавление строк в словарь сводится к добавлению очередного узла в дерево и присвоению данному узлу уникального индекса, соответствующего значению счетчика индексов, которое после добавления строки увеличивается на единицу (начальное значение счетчика равно 259). Стандарт V.42bis предписывает, что добавление должно производиться только в том случае, когда длина добавляемой строки не превышает некоторого заданного значения (данное значение выбирается непосредственно перед началом кодирования).
Одно из главных различий между рассматриваемым алгоритмом и алгоритмом LZW заключается в разном подходе к решению проблемы переполнения словаря. В отличие от алгоритма LZW, в алгоритме, рекомендуемом комитетом CCITT, при достижении общим количеством узлов некоторого предела реинициализация дерева не производится. Здесь действует несколько иной механизм, работа которого состоит в присвоении новой строке индекса уже имеющейся в словаре строки с последующим удалением этой старой строки из словаря поиска. Для избежания затруднений с обновлением дерева удаляются только строки, соответствующие листовым узлам. Детально механизм работает следующим образом. В случае, когда значение в счетчике индексов достигает своего предельного значения, счетчик сбрасывается до своего начального состояния (259) и увеличивается до тех пор, пока узел, соответствующий его текущему состоянию, не окажется листовым (заметим, что корневые узлы в данном процессе не участвуют, так как значение счетчика никогда не совпадает с индексами этих узлов). Индекс данного листового узла присваивается новой строке. В дальнейшем при добавлении каждой новой строки должна осуществляться вышеописанная процедура.
Как известно, алгоритм LZW в некоторых ситуациях оказывается крайне неэффективным. Данная особенность была учтена при разработке стандарта V.42bis. Стандарт предусматривает два режима обработки информации: режим сжатия (compressed mode) и прозрачный режим (transparent mode). В режиме сжатия информация кодируется с применением описанного выше алгоритма, а в прозрачном режиме она поступает на выход в исходном (незакодированном) виде. Прозрачный режим задействуется в том случае, когда кодирование начинает приводить к увеличению объема исходного представления информационного потока. Важно отметить, что при работе в прозрачном режиме информация по-прежнему обрабатывается описанным алгоритмом сжатия, однако при этом не генерируется выходной код. То же самое происходит при работе в прозрачном режиме на этапе декодирования. Использование “холостого хода” обуславливается необходимостью определения момента возвращения системы обработки информации обратно в режим сжатия. Решение о переключении между режимами должно осуществляться на основе информации об эффективности кодирования в текущий момент времени. Процедура принятия такого решения специально не оговаривается в стандарте, что дает разработчикам аппаратуры некоторую свободу при его реализации.
Управление сеансом обработки информации в реализациях рассматриваемого стандарта осуществляется посредствам передачи служебной информации. Для каждого режима обработки информации стандартом предусматривается три служебные кодовые комбинации. В режиме сжатия это служебные индексы ETM (информирует декодер о переходе в прозрачный режим), FLUSH (информирует декодер о необходимости выравнивания кода по границе следующего октета) и STEPUP (информирует декодер о расширении кодового представления индексов), а в прозрачном режиме это служебные символы ECM (информирует декодер о переходе в режим сжатия), EID (символизирует наличие служебного символа в данных) и RESET (информирует декодер о необходимости реинициализации словаря). Здесь может возникнуть вполне законный вопрос: благодаря чему становится возможной передача служебных символов в прозрачном режиме обработки информации? (Дело в том, что исходное информационное представление обычно допускает использование только символов обычного алфавита сообщений.) В стандарте V.42bis для этого предлагается применять эскейп-символы. В качестве эскейп-символа всегда выступает какой-то символ исходного алфавита сообщений. При поступлении такого символа на вход декодера следующий за ним символ рассматривается как служебный. В случае, когда символ, выступающий в роли эскейп-символа, встречается в обрабатываемой информации, он выводится в выходной поток вслед за служебным символом EID. При этом роль эскейп-символа передается другому символу (механизм передачи строго регламентирован). Служебные символы, а также информационные символы записываются в восьмибитовом представлении. Неиспользуемые значения служебных символов (от 3 до 255) зарезервированы для будущего применения.
Принято считать, что
рассмотренный алгоритм сжатия по эффективности превосходит алгоритмы, описываемыми
в протоколах
MNP5
и MNP7.
Однако, в действительности дело обстоит несколько иначе. В [25]
приводятся
результаты сравнения эффективности использования протокола MNP5
и
реализации стандарта V.42bis в модеме
AnCom-ST
2442. Некоторые
из них представлены в следующей таблице.
|
Файл |
(байт) |
(байт/с) |
(байт/с) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Как видно из результатов, алгоритм, предлагаемый в стандарте V.42bis, больше всего подходит для сжатия текстовой информации. Применение данного алгоритма к другим типам информации часто оказывается неоптимальным решением.
1.3 Управление сжатием в протоколе PPP
Протокол управления сжатием CCP (Compression Control Protocol) [14], входящий в протокол PPP (Point-to-Point Protocol), регламентирует использование различных алгоритмов сжатия информации при ее передаче между оконечными узлами линий связи. Он непосредственно отвечает за выбор, настройку и управление процессами сжатия во время соединения. Протокол допускает использование следующих алгоритмов сжатия:
Один из приведенных алгоритмов уже был подробно описан выше. Данный подраздел посвящен рассмотрению алгоритмов Predictor, Stac Electronics LZS и Microsoft PPC.OUI Predictor type 1 Predictor type 2 Puddle Jumper Hewlett-Packard PPC Stac Electronics LZS Microsoft PPC Gandalf FZA V.42bis compression BSD LZW Compress.
1.3.1 Алгоритм Predictor
Алгоритм Predictor [15] - один из наиболее быстрых алгоритмов сжатия. Он относится к алгоритмам словарной группы и использует так называемое контекстно-зависимое кодирование.
Во время работы алгоритма Predictor поддерживается структура, именуемая таблицей предсказаний (guess table). Физически таблица предсказаний представляет собой массив из 65536 ячеек, каждая из которых содержит один символ 256-символьного алфавита. Во время работы алгоритма содержимое таблицы предсказаний используется для предсказания появления очередного обрабатываемого символа с целью выбора способа его кодирования. Обработка символа производится следующим образом. По нескольким символам, непосредственно предшествующим кодируемому символу, вычисляется хэш-индекс - число в интервале от 0 до 65535. Содержимое соответствующей ячейки таблицы предсказаний сравнивается с кодируемым символом. В случае совпадения (верное предсказание) символ кодируется единичным битом; в случае же отсутствия совпадения (ошибочное предсказание) код для символа представляет собой совокупность нулевого бита и исходного восьмибитового представления символа. Для удобства биты, указывающие на наличие или отсутствие совпадений, объединяются в блоки по 8 битов (октеты). Последним этапом обработки является запись обработанного символа в ячейку, символ в которой использовался для предсказания (обновление таблицы предсказаний).
Для осуществления корректной интерпретации получаемой кодовой последовательности таблица предсказаний должна поддерживаться и на этапе декодирования, причем все изменения в таблице должны производиться синхронно на одних и тех же этапах кодирования и декодирования. Процесс декодирования весьма прост. Когда встречается бит, указывающий на совпадение, в выходной поток выводится символ, принадлежащий ячейке таблицы, соответствующей хэш-индексу, вычисляемому по нескольким последним декодированным символам. Если бит указывает на отсутствие совпадения, декодирование сводится к простому копированию символа из кодовой последовательности в выходную последовательность. После декодирования очередного символа запускается процедура обновления таблицы предсказаний, полностью эквивалентная процедуре обновления, производимой на этапе кодирования.
Алгоритм Predictor не получил широкого распространения на практике. Причиной тому, скорее всего, послужила его недостаточная эффективность.
1.3.2 Алгоритм Stac Electronics LZS
Как следует из названия, правами на алгоритм LZS [8] владеет фирма Stac Electronics. Алгоритм принадлежит семейству LZ77 и является производным от алгоритма LZSS.
В процессе обработки информации алгоритмом LZS в словаре, в роли которого выступают 2 килобайта обработанной информации, каждый раз производится поиск строки, имеющей достаточно длинное совпадение с текущей кодируемой символьной последовательностью. Минимальная длина совпадения равна двум байтам. В случае отсутствия совпадений приемлемой длины первый символ кодируемой последовательности выводится в его исходном восьмибитовом представлении (незакодированный символ). Кодовые комбинации, описывающие совпадения и незакодированные символы, различаются служебными битами: 0 означает незакодированный символ, а 1 - совпадение.
Наибольший интерес для рассмотрения в алгоритме LZS представляет способ кодирования совпадений. Кодовая комбинация, описывающая совпадение, так же, как и в алгоритме LZSS, состоит из двух частей: смещения позиции идентичной строки в буфере поиска и длины совпадения. Смещение может быть записано с использованием 7 или 11 битов. Способ записи смещения указывается с помощью служебного бита: 0 соответствует 11-битовому представлению смещения, а 1 - 7-битовому. Нулевое смещение в 7-битовом представлении зарезервировано для указания конца файла.
Длина совпадения записывается
префиксным кодом переменной длины. Небольшим длинам совпадений ставятся
в соответствие длинные префиксные коды. Соответствие между длинами совпадений
и префиксными кодами представлено в следующей таблице:
| Длина |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Алгоритм LZS является алгоритмом, реально используемым в коммуникационных технологиях. Данный алгоритм часто реализуется на аппаратном уровне в маршрутизаторах.
1.3.3 Алгоритм Microsoft PPC
Алгоритм Microsoft PPC был предложен фирмой Microsoft как часть отдельного протокола сжатия Microsoft PPCP (PPCP - Point-to-Point Compression Protocol) [12]. Данный алгоритм так же, как и предыдущий алгоритм, является словарным алгоритмом семейства LZ77.
Во время работы алгоритма производится поиск совпадений в части обработанной информации, непосредственно предшествующей текущей обрабатываемой позиции. Размер словаря равен 8 килобайтам. Как обычно, при кодировании используются кодовые комбинации двух типов: первые описывают незакодированные символы, а вторые предназначены для описания совпадений. Минимальная длина совпадения равна 3 байтам.
Особого внимания заслуживает оригинальный способ кодирования, используемый в алгоритме Microsoft PPC. Незакодированные символы, числовое представление которых не превышает 127, выводятся в выходной поток в своем исходном виде. Для каждого из оставшихся 128 символов кодовая комбинация получается добавлением к 7 младшим битам исходного представления символа префикса “10”.
Код совпадения стандартным образом делится на код смещения совпадения в словаре поиска и код длины совпадения. Смещение может быть закодировано одним из трех способов. Если смещение не превосходит 63, код для смещения получается добавлением префикса “1111” к 6-битовому представлению смещения. В случае, когда смещение находится в интервале от 64 до 320, код получается добавлением префикса “1110” к 8-битовому представлению разности смещение-64. Во всех остальных случаях код смещения получается добавлением префикса “110” к 13-битовому представлению разности (смещение - 320).
Способ кодирования длин
совпадений представлен в следующей таблице.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Благодаря наличию словаря поиска большего размера и более эффективного способа кодирования, алгоритм Microsoft PPC, как правило, превосходит по степени сжатия алгоритм Stac Electronics LZS. Тем не менее, алгоритм Microsoft PPC значительно реже применяется на практике, что, скорее всего, обусловлено его повышенной сложностью.
1.4 Сжатие заголовков пакетов передачи информации
Проблема сжатия заголовков пакетов передачи информации является весьма актуальной, ибо нередко встречаются ситуации, когда размер заголовка оказывается сравнимым с размером всего пакета. К примеру, очень часто при совместном использовании интерактивной и групповой пересылки данных для уменьшения времени ожидания интерактивного пакета большой массив передается с помощью маленьких пакетов. Так как количество таких пакетов оказывается очень большим, экономичное представление их заголовков может существенно повысить скорость передачи. В [10] было показано, что применение стандартных алгоритмов в данном случае неоптимально, и более эффективный подход связан с использованием специализированных алгоритмов сжатия.
Уменьшение объема заголовков пакетов передачи информации становится возможным благодаря тому, что пакеты, принадлежащие единому пакетному потоку, часто содержат схожие значения в некоторых полях заголовка. Все поля заголовка могут быть условно разделены на три типа: поля с неопределенными (случайными) значениями, поля с постоянными значениями и поля с плавно меняющимися значениями. Сжатие заголовков достигается за счет использования экономных способов представления полей двух последних типов.
Базовым объектом в технологиях сжатия заголовков пакетов передачи информации является контекст заголовка пакета. Контекстом заголовка пакета называется совокупность значений его полей, передаваемых в особом экономичном формате. В процессе кодирования и декодирования осуществляется хранение контекстов обработанных (переданных или полученных) пакетов. При этом каждому контексту присваивается его уникальный идентификатор.
Рассмотрим в общих чертах процедуру эффективной передачи заголовка коммуникационного пакета. Поля с постоянными или плавно меняющимися значениями, как правило, непосредственно не передаются, а вместо этого осуществляется передача некоторой структуры, содержимое которой позволяет восстановить искомые значения полей. Данная структура обычно включает в себя идентификатор контекста некоторого обработанного пакета, совокупность флагов, указывающих на характер различий между значениями тех или иных полей заголовков обработанного и текущего передаваемого пакетов, и представление этих различий в особом формате. Поля заголовков, содержащие неопределенные значения, передаются в их исходном представлении в составе указанной структуры. Эффективность передачи заголовка зависит от конкретного способа представления различий между содержимым полей заголовков текущего передаваемого пакета и обработанного пакета, контекст которого указывается с использованием идентификатора. Чаще всего для представления различий применяется так называемое дельта кодирование [10].
Алгоритмы сжатия пакетов передачи информации обладают очень высокой эффективностью. Так, объем заголовков пакетов UDP и TCP может быть уменьшен до 4-7 октетов. (Заметим, что заголовки этих пакетов обычно включают в себя двухоктетную контрольную сумму.) Подобная эффективность позволяет существенно повышать скорость передачи информации по медленным линиям связи.
1.5 Метод ADPCM
Адаптивная дифференциальная импульсно-кодовая модуляция (ADPCM) является частным случаем дифференциального кодирования. Данный метод предложен в качестве стандарта комитетом CCITT.
Согласно рекомендации
G.726
к стандарту, метод ADPCM
может быть
использован для осуществления двустороннего преобразования PCM-сигнала,
передаваемого по каналу с пропускной способностью 64 кбит/c, в
PCM-сигнал,
предназначенный для передачи по каналам с минимальными пропускными способностями
40, 32, 24 или
16 кбит/c. Рассмотрим вкратце процесс
кодирования и декодирования методом ADPCM.
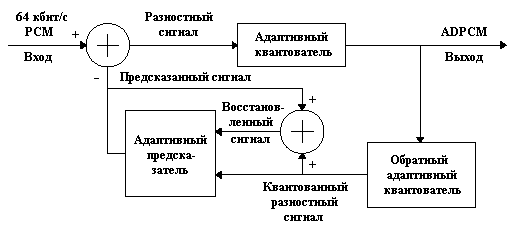
На приведенном выше рисунке изображена структурная схема процесса кодирования PCM-сигнала методом ADPCM. Во время работы метода адаптивный предсказатель осуществляет предсказание уровня поступающего равномерно квантованного сигнала. Входной сигнал имеет 256 уровней квантования и частоту дискретизации 8 кгц. В сумматоре происходит алгебраическое сложение входного и предсказанного сигнала. Разностный сигнал поступает в адаптивный квантователь, где производится логарифмическое квантование. Число уровней квантования, согласно стандарту, может быть равно 16, 8, 4 или 2. (Соответственно сигнал может быть передан по каналам с минимальными пропускными способностями 40, 32, 24 или 16 кбит/c.) Другие параметры квантования частично определяются в стандарте, а частично зависят от характеристик обрабатываемого сигнала.
С выхода адаптивного квантователя сигнал одновременно поступает в обратный адаптивный квантователь и в канал передачи. Обратный адаптивный квантователь предназначен для перевода логарифмически квантованного PCM-сигнала в равномерно квантованный разностный сигнал. Получаемый разностный сигнал может не совпадать с исходным разностным сигналом. Обратное преобразование необходимо для того, чтобы обеспечить одинаковое предсказание на этапах кодирования и декодирования.
С выхода обратного адаптивного квантователя равномерно квантованный разностный сигнал одновременно поступает на вход адаптивного предсказателя и на вход сумматора. Последний осуществляет суммирование данного сигнала с предсказанным сигналом. Полученный в результате суммирования сигнал также поступает на вход адаптивного предсказателя.
Адаптивный предсказатель осуществляет предсказание на основе 6 последних выборок обрабатываемого сигнала. При этом учитываются особенности данного сигнала. (Учет производится посредствам адаптивного изменения параметров предсказывающей функции.)
На следующем рисунке приведена структурная схема процесса декодирования.
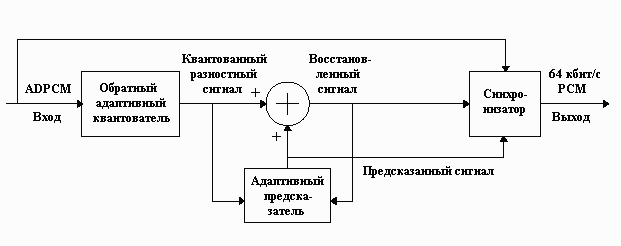
Процесс декодирования в методе ADPCM схож с процессом кодирования. ADPCM-сигнал поступает на вход обратного адаптивного квантователя. Равномерно квантованный разностный сигнал одновременно поступает на сумматор и адаптивный предсказатель. На сумматор также поступает предсказанный сигнал. Полученный в результате сложения восстановленный сигнал одновременно поступает в адаптивный предсказатель и синхронизатор. В синхронизатор также поступает входной ADPCM-сигнал. Синхронизатор служит для устранения накопленного временного искажения. С выхода синхронизатора PCM-сигнал поступает в выходной канал с пропускной способностью 64 кбит/c.
Правильное декодирование сигнала становится возможным благодаря одинаковым предсказаниям, вычисляемым адаптивным предсказателем на этапах кодирования и декодирования. Отметим, что одним из важных условий корректного декодирования является отсутствие ошибок в канале передачи.
Метод ADPCM чаще всего применяется для сжатия аудио сигналов и, в особенности, голосовых сообщений. Он нашел свое применение во многих устройствах передачи звуковой информации, начиная с голосовых модемов и заканчивая мобильными телефонами.
2. Перспективные технологии сжатия при передаче информации
Прогресс вычислительной техники повсеместно ставит на первый план новые эффективные технологии. Самые современные алгоритмы и методы сжатия информации с потерями и без потерь постоянно внедряются в практические приложения. К огромному сожалению, технологии связи остались на сегодняшний день чуть ли не единственной областью, где существующим методикам сжатия не уделяется должное внимание.
Автором были проведены испытания, целью которых было выяснение того, насколько эффективно наработанные технологии сжатия используются для увеличения скорости передачи информации. Во время испытаний несколько файлов, содержимое которых относится к наиболее распространенным типам информации, передавались между двумя достаточно удаленными пунктами линии связи. Информация поступала через телефонную линию в узел Internet-провайдера, а затем через глобальную сеть Internet осуществлялась ее дальнейшая передача удаленному абоненту. Во время передачи в оконечных пунктах линии производилось кодирование и декодирование передаваемой информации с применением наиболее удачных на сегодняшний день реализаций методов PPM, BW, а также двухуровневой словарной схемы семейства LZ77 (LZ). Для осуществления обработки информации в обоих случаях использовался компьютер Pentium 166 (32 мегабайта оперативной памяти) под управлением операционной системы Windows 98. Обработчикам информации в процессе кодирования и декодирования выделялось по 5 мегабайт оперативной памяти. Для осуществления передачи информации через телефонную линию использовался модем 3Com Sporster 56k V.90 (максимальная скорость передачи - 33600 бит/с).
Ниже приведены результаты
проведенных испытаний. Было учтено суммарное время кодирования, декодирования
и передачи. Коэффициенты в таблице показывают, во сколько раз применение
той или иной методики сжатия позволило увеличить скорость передачи информации.
|
|
(килобайт) |
протоколы |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Числа говорят сами за себя: современные методы сжатия оказываются существенно более эффективными в сравнении с методами, реально применяемыми на практике. В случае с файлом “oranges.jpg”, содержащим малоизбыточные данные и практически не поддающимся сжатию, небольшое падение производительности при использовании новых методик сжатия связано с отсутствием в них алгоритма предварительного детектора, функцией которого является определение возможности уменьшения объема представления той или иной информации. При наличии такого детектора падения производительности можно избежать.
Необходимо признать, что во время испытаний были задействованы серьезные вычислительные ресурсы. Однако на сегодняшний день большинство вычислительных систем обладают производительностью, превосходящей производительность системы, использованной для испытаний.
Исходя из вышесказанного,
можно сделать вывод о необходимости применения в коммуникационных технологиях
современных высокоэффективных алгоритмов сжатия.
Литература
- Barbir A., Carr D., Simpson W. PPP Gandalf FZA Compression Protocol. - RFC1993. - August, 1996.
- Casner S., Jacobson V. Compressing IP/UDP/RTP Headers for Low-Speed Serial Links. - RFC2508. - February, 1999.
- Degermark M., Nordgren B., Pink S. IP Header Compression. - RFC2507. - February, 1999.
- Deutsch P. , Gailly J-L. ZLIB Compressed Data Format Specification version 3.3. - RFC1950. - May, 1996. - http://compression.ru/download/articles/lz/rfc1950_pdf.rar
- Deutsch P. DEFLATE Compressed Data Format Specification version 1.3. - RFC1951. - May, 1996. - http://compression.ru/download/articles/lz/rfc1951_pdf.rar
- Deutsch P. GZIP file format specification version 4.3. - RFC1952. - May, 1996.
- Engan M., Casner S., Bormann C. IP Header Compression over PPP. - RFC2509. - February, 1999.
- Friend R., Simpson W. PPP Stac LZS Compression Protocol. - RFC1974. - August, 1996.
- Friend R., Monsour R. IP Payload Compression Using LZS. - RFC2395. - December, 1998.
- Jacobson V. Compressing TCP/IP headers for low-speed serial links. - RFC1144. - February, 1990.
- Mathur S., Lewis M. Compressing IPX Headers Over WAN Media (CIPX). - RFC1553. - December, 1993.
- Pall G. Microsoft Point-To-Point Compression (MPPC) Protocol. - RFC2118. - March, 1997.
- Pereira R. IP Payload Compression Using DEFLATE. - RFC2394. - December, 1998.
- Rand D. The PPP Compression Control Protocol (CCP). - RFC1962. - June, 1996.
- Rand D. PPP Predictor Compression Protocol. - RFC1978. - August, 1996.
- Salomon D. Data compression. - Springer. - 1997. - P. 56-62.
- Schneider K., Friend R. PPP LZS-DCP Compression Protocol (LZS-DCP). - RFC1967. - August, 1996.
- Schneider K., Venters S. PPP for Data Compression in Data Circuit-Terminating Equipment (DCE). - RFC1976. - August, 1996.
- Schremp D., Black J., Weiss J. PPP Magnalink Variable Resource Compression. - RFC1975. - August, 1996.
- Schryver V. PPP BSD Compression Protocol. - RFC1977. - August, 1996.
- Woods J. PPP Deflate Protocol. - RFC1979. - August, 1996.
- Shacham A., Monsour R., Pereira R., Thomas M. IP Payload Compression Protocol (IPComp). - RFC2393. - December, 1998.
- CCITT Data Compression Procedures for Data Circuit Terminating Equipment (DCE) Using Error Correction Procedures. Recommendation V.42 bis. - CCITT. - January, 1990.
- The Implementation of G.726 Adaptive Differential Pulse Code Modulation (ADPCM) on TMS320C54x DSP // Texas Instruments Europe. - July, 1997.
-
Дудоров Ю. Протокол сжатия данных
для модемов V.42bis. - http://www.modem.od.ua/lib/lib_protocol_v42bis.html или
http://compression.ru/download/
articles/lz/dudorov_v42bis_compression.htm
Posted in May 2000.
Текст с "косметическими" исправлениями Максима Смирнова, 28.05.2003