Смотрите также материалы:
- Предсказание по частичному совпадению (PPM)
- Арифметическое сжатие
- Сжатие с помощью грамматических моделей
- Обзоры универсальных алгоритмов сжатия данных
- Книга "Методы сжатия данных". Раздел 1 "Методы сжатия без потерь"
Экспериментальный
однофайловый компрессор hipp
v0.5819 (19/08/2005)
Богатов Роман, Омский государственный технический университетHipp v0.5819 с исходниками 59 Кб (Visual C++ 7.0)
Основные особенности (в направлении которых и ставится эксперимент):
- двойное ограничение глубины суффиксного дерева при использовании объединения цепочек детерминированных узлов;
- использование фиксировано-удалённых контекстов.
Фиксировано-удалённые контексты (далее – fd-контексты, от fixed distance contexts) имеют вид x*, x**, xx*, x***, xx**, xxx*, x**** и т.д. (где х – конкретные опорные символы, * – позиции, занимаемые любыми символами), т.е. являются частным случаем разреженных контекстов (sparse contexts), когда все опорные символы сгруппированы слева и отделены от кодируемого символа с пропуском некоторого фиксированного числа символов. Распространённой практикой использования разреженных контекстов является запоминание только одного – последнего встретившегося – символа. Эксперимент с fd-контекстами заключается в учёте полной статистики по встречаемости символов в этих контекстах и увеличении степени сжатия данных с использованием этой статистики. (См. результаты экспериментов ниже.)
Hipp использует полное смешивание по следующей схеме. Веса прогнозов по сплошным контекстам (т.е. "обычным", не разреженным контекстам) рассчитываются по методу PPMY Евгения Шелвина с использованием заимствованных из PPMY таблиц коэффициентов; веса fd-контестов – по тем же формулам, но с постоянными коэффициентами; детерминированные контексты, выходящие за пределы первого ограничения глубины, обрабатываются особо. Кодирование символа происходит дихотомически (aka "унарно") c поэтапной оценкой каждого возможного значения символа и кодирования результата. Унарные вероятности моделей сплошных и fd-контекстов проходят двумерную вторичную оценку с интерполяцией (aka SSE2), реализованную Е. Шелвиным, и смешиваются с помощью также вторично оцениваемого коэффициента.
Для вторичного оценивания используются упрощённые SSE-контексты. Для сплошных контекстов - ничего нового. Для fd-контекстов и коэффициента смешивания моделей наиболее существенным компонентом является уникальный индекс шаблона fd-контекста, внёсшего наибольший вклад в совокупную оценку. В качестве двух интерполируемых аргументов используются несмешанные унарные вероятности моделей.
Наиболее существенные недоработки:
- отсутствует какое-либо масштабирование счётчиков частот (recency scaling, rescaling);
- реализован самый простейший метод выживания при достижении ограничения по памяти, сводящий на нет весь достигнутый к тому моменту выигрыш в сжатии;
- примитивная схема смешивания прогнозов моделей сплошных и fd-контекстов и непроработанные SSE-контексты;
- при использовании fd-контекстов не может быть использовано ОДУ (подружить их можно, но не так быстро, как предполагалось);
- в случае fd-контекстов требуется дифференциация счётчиков "оптимальности" (используемых Е. Шелвиным для расчёта весов полного смешивания) в зависимости от глубины и шаблона fd-контекста;
- прилагаемый исходный код вообще-то не планировался к опубликованию и совершенно не причёсан :о)
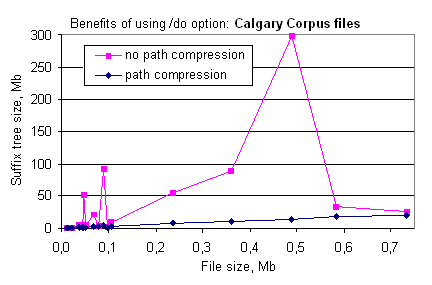
(Изображены результаты прогона 18 файлов тестового набора Calgary Corpus при ограничении глубины MaxOrder=1706. В Calgary Corpus есть только один файл, содержащий повторяющийся блок длины больше 1706, pic, которому соответствует пик на графике в 300 Мб. Для pic полное суффиксное дерево (MaxOrder=36313) с ОДУ занимает всего 15,4 Мб; без ОДУ уже при MaxOrder=8000 занимает 926 Мб. Тот факт, что в hipp использованы 32-битные счётчики частот (~1/6 объёма дерева без ОДУ) и 18-байтовая структура узла (содержащая дополнительные параметры, вместо минимальной 5-байтовой; ~1/3 объёма дерева), не искажает качества графика. Здесь же следует отметить, что для построения дерева с ОДУ требуется меньше времени (главным образом, из-за экономии памяти), а в целом сжатие с ОДУ занимает приблизительно столько же времени, как без ОДУ.)
При реализации ОДУ использовался более сложный подход, чем замена symbol-transition на string-transition (см., например, диссертацию S. Bunton), на основе собственных структур (см. файл NodeStruct.inl). Самая большая проблема, с которой пришлось столкнуться, – это эмуляция должных значений счётчиков "оптимальности" объединённых узлов (чтобы не хранить их явно; иначе бы вся красота ОДУ сошла на нет). Реализованный метод требует два дополнительных статических массива – для счётчиков встречаемости узлов и счётчиков оптимальности – по (MaxOrder+1) элементов каждый.
Использование второго ограничения глубины суффиксного дерева (MaxOrder2, MaxOrder1<=MaxOrder2) позволяет качественно обрабатывать файлы, содержащие большие повторяющиеся блоки, при тех же расходах памяти и небольших дополнительных затратах времени. Пример:
Исходные файлы:
book1 768771
book1_x10 7687710 (10 склеенных book1)
Оборудование: Pentium 4 2400MHz, 1Gb DDR400, Seagate 60Gb, Windows XP Pro + SP2.
Параметры Память, Время, Архив,
запуска Hipp 0.5819 Мб с Кб
book1_x10/o4/do4 32,8 50 1758
book1_x10/o4/do256 32,8 53 314
book1_x10/o4/do1024 32,8 62 212
Для сравнения – сжатие одного book1:
book1/o4/do4 25,6 5 209
(т.е. почти достигнут размер однократного book1)
Прочие архиваторы
(сжатие book1_x10: память, время, размер):
PAsQDa v3.9 -8 930Mb 6344 176
PAsQDa v3.9 -2 32Mb 1324 1741
Durilca v.0.4b –o64 -t1 940Mb 22 179
Durilca v.0.4b –o64 940Mb 22 199
PAQAR v4.0 -7 ~900Mb 1891 192
PAQAR v4.0 -3 ~55Mb 2054 1752
WinRK 2.0 PWCM 900Mb 870 200
PPMonstr var.I –o32 225Mb 12 201
PPMonstr var.I –o16 32Mb 23 991
PPMonstr var.I –o32 32Mb 26 1295
ash /o33 /s255 480Mb 85 203
ash /o17 /s255 186Mb 66 222
ash /o65 /s255 >1Gb 94 364
PPMd var I. –o16 89Mb 2 224
PPMd var I. –o9 26Mb 2 569
RAR 3.40 -m5 3 212
RAR 3.40 -m5 –mc63:128t+ 4 212
RAR 3.40 -m5 –mc16:32t+ 4 534
Slim! v0.016 –w22 18 216
Slim! v0.23d –o32 240Mb 52 218
Slim! v0.23d –o16 140Mb 51 230
Slim! v0.23d –o16 70Mb 81 915
EPM r9 –c128 71 1960
EPM r9 –c064 70 1963
EPM r9 -c999 101 1963
Как видно из первой таблицы, благодаря ОДУ hipp использовал всего 32,8 Мб памяти для контекстного моделирования 4-го порядка (из которых суффиксное дерево занимает только 2,7 Мб; остальное – невостребованные SSE-массивы, кэширование всего файла целиком и пр.) и благодаря увеличению MaxOrder2 до 1024 "учёл" десятикратность входных данных, затратив на 25% больше времени (хотя порядок модели увеличился в 256 раз).
На обычных файлах (не являющихся склейкой одинаковых блоков :о) ситуация двоякая. Типичные благоприятный и неблагоприятный случаи на примере файлов news из Calgary Corpus и fp.log с www.maximumcompression.com:
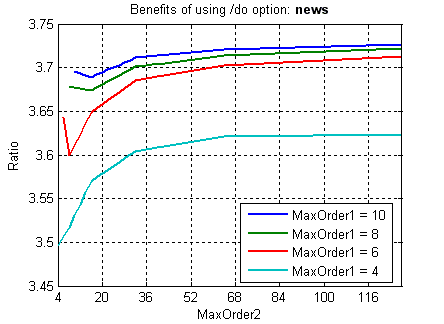
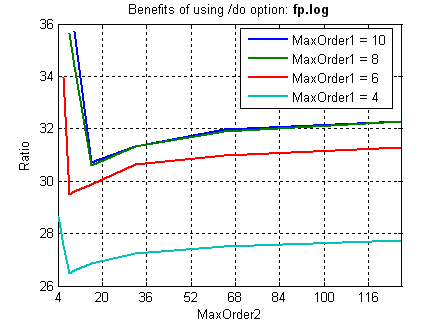
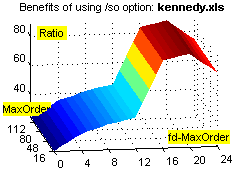
Фиксировано-удалённые контексты обеспечивают существенное увеличение степени сжатия на файлах с табличной структурой (xls, dbf и т.п.), а также исполняемых файлах, и в то же время незначительно ухудшают степень сжатия при применении к "неблагоприятным" данным (например, текстам). Зависимость расходов времени и памяти от объёма входных данных при этом остаётся линейной (хотя это ни о чём не говорит – зависимость остаётся линейной даже при привлечении всех возможных разреженных контекстов ограниченной глубины :о). Смотрим зависимости степени сжатия (ratio), времени (time) и использованной памяти (used memory) от глубины сплошных контекстов (MaxOrder) и глубины fd-контекстов (fd-MaxOrder) при сжатии файлов kennedy.xls из Canterbury Corpus, obj2 и pic из Calgary Corpus:
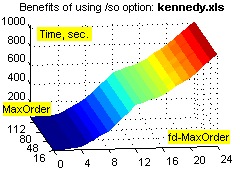
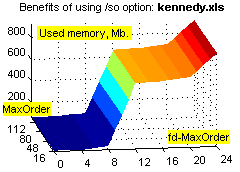
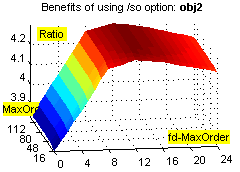
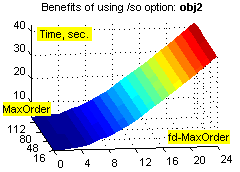
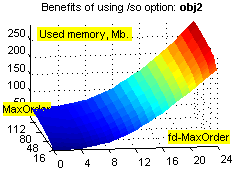
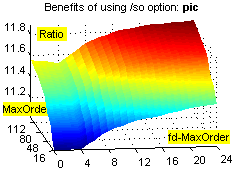
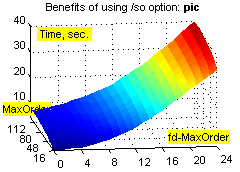
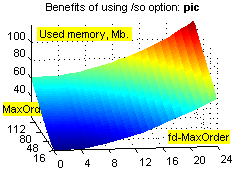
Результаты большого теста. Исходные данные: годовая 1С-база одного из предприятий (207 Мб) + несколько годовых xls-отчётов (17 Мб), всего 730 файлов 21 типа. Т.к. hipp не использует никаких фильтров, не разбивает входные данные на области, не масштабирует статистику, неважно себя ведёт при дефиците памяти, не сохраняет ни имени файла, ни пути... :о), приходится делать следующий манёвр. Исходные данные консолидируются в rar-архивы без сжатия, раздельно по расширениям, с максимальным размером тома 1 Мб (например, rar a -ds -m0 -r -v1m -vn _dbf *.dbf); мелкие и одиночные файлы (с расширениями txt, rtf, xml, als, tls, cfg, st, tip, spl, log, efd, lst, id; суммарный размер 700 Кб) – в один архив. В результате исходные данные представляют собой 230 файлов (225 Мб), размером не более 1 Мб каждый, удобных к обработке однофайловым компрессором. Обратное преобразование осуществляется командой rar x *.rar.
Совокупная степень сжатия полученных томов по отдельности представлена в таблицах:
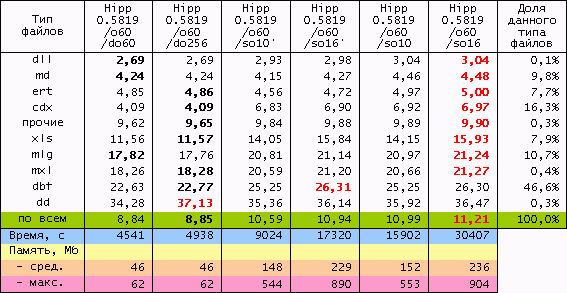
(Лучшее значение степени сжатия в первых двух столбцах выделено полужирным; лучшее по строке - красным. Здесь, во-первых, видно, что использование двойного ограничения глубины суффиксного дерева в среднем способствует увеличению степени сжатия (второй столбец). Значения глубины fd-контекстов со штрихом – эксперимент по исключению fd-контекстов с одним опорным символом, т.е. вида x*, x**, x***, x**** и т.д., являющихся самыми ресурсоёмкими и, как может показаться, наименее важными. Но небольшой выигрыш в ресурсах при этом оказался несоответственным потере в степени сжатия: совокупные результаты запуска с параметром /so16' , например, по всем показателям проигрывают более сильному и экономичному сжатию с параметром /so10.)
Два столбца с лучшими показателями hipp (без и с использованием fd-контекстов) представлены в сравнении с другими известными архиваторами:
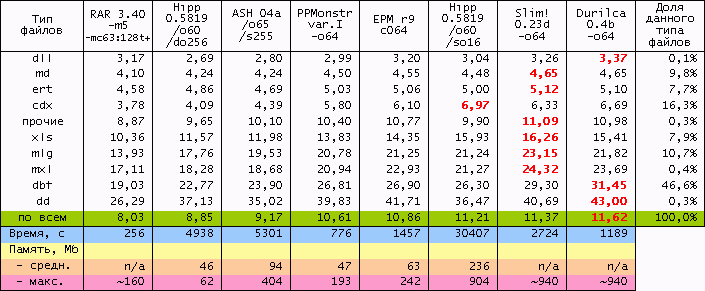
(Тяжеловесы типа PAQAR, PAsQDa и WinRK не тестировались :о( Лучшее значение степени сжатия по строке выделено полужирным. Итоговые степени сжатия также отображены на диаграмме ниже. Как видно, рейтинг hipp с fd-контекстами в таблице обусловлен хорошим сжатием cdx и xls-файлов, составляющих почти четверть входных данных. О качестве этого результата говорит также тот факт, что по сжатию dbf-файлов, составляющих 46,6%, hipp занимает аж пятое место, что не мешает ему оставаться на третьем месте по совокупной степени сжатия.)
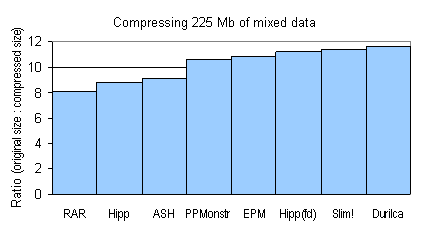
Основные выводы. Ещё раз повторюсь, что эксперимент ставился в двух направлениях: повышение степени сжатия при использовании ОДУ + двойного ограничения глубины дерева и fd-контекстов.
ОДУ, само по себе, существенно экономит память, но применимо только для "простых" суффиксных деревьев, узлы которых не содержат специфических параметров. ОДУ реализуемо, например, для узлов с обычными счётчиками встречаемости и оптимальности узла, а также при использовании простого безусловного масштабирования этих счётчиков.
Если ОДУ реализовано, то двойное ограничение глубины суффиксного дерева является готовой и удобной альтернативой LZ-субмоделям, предназначенным для обработки больших повторяющихся блоков данных. Даже такое грубое использование двойного ограничения, как в настоящей версии hipp, является серьёзным подспорьем, особенно при малых значениях MaxOrder1.
Учёт полной статистики по встречаемости символов в fd-контекстах на определённых типах данных позволяет hipp при всей его недоработанности достигать уровня сжатия хорошо проработанных лидирующих архиваторов. Вскользь упомянутый эксперимент с запрещением fd-контекстов с одним опорным символом говорит о ценности именно полной статистики по всем встречающимся символам в fd-контекстах контекстах. Хотелось бы обратить общественное внимание на то, что тема использования разреженных контекстов для универсального сжатия мало исследована и ещё меньше освещена в каких-либо публикациях.
Благодарю Бога (такого заботливого Отца), кафедру АСОИУ ОмГТУ (ставшую моей родиной) и Евгения Шелвина (за щедрое консультирование и дружбу)!
Имэйл автора для отзывов: fwd2bogatov на Яндекс.ру.
наверх
Смотрите также материалы:
- Предсказание по частичному совпадению (PPM)
- Арифметическое сжатие
- Сжатие с помощью грамматических моделей
- Обзоры универсальных алгоритмов сжатия данных
- Книга "Методы сжатия данных". Раздел 1 "Методы сжатия без потерь"